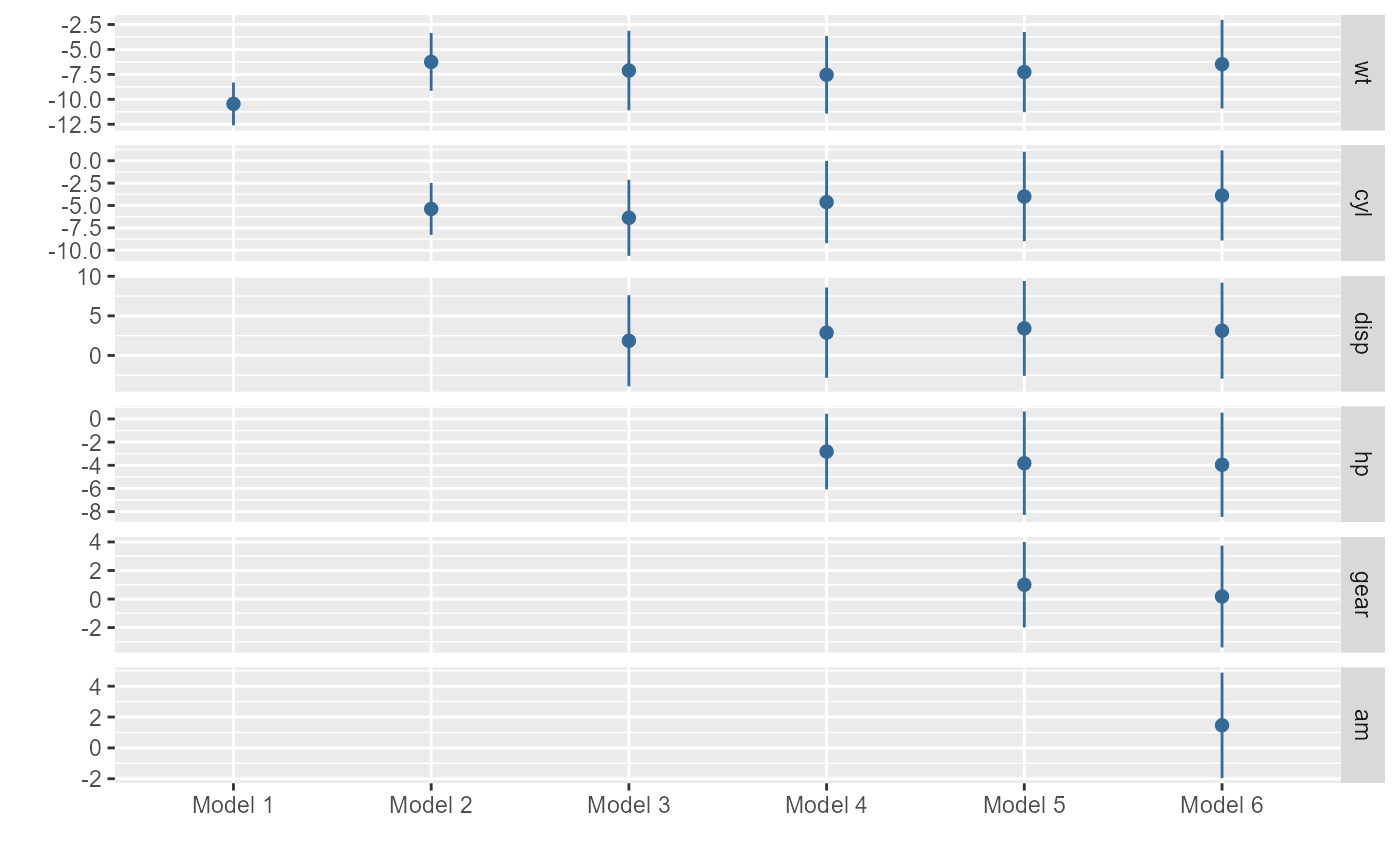
small_multiple is a function for plotting regression results of multiple models as a 'small multiple' plot
small_multiple(
x,
ci = 0.95,
margins = FALSE,
dodge_size = 0.4,
show_intercept = FALSE,
show_stats = FALSE,
stats_tb = NULL,
stats_digits = 3,
stats_compare = FALSE,
stats_verbose = FALSE,
stats_size = 10,
stats_padding = unit(c(4, 4), "mm"),
stats_layout = c(2, -1, 1),
model_order = NULL,
submodel_order = NULL,
axis_switch = FALSE,
by_2sd = FALSE,
dot_args = list(size = 0.3),
...
)Arguments
- x
Either a model object to be tidied with
tidy, or a list of such model objects, or a tidy data frame of regression results (see 'Details').- ci
A number indicating the level of confidence intervals; the default is .95.
- margins
[Suspended] A logical value indicating whether presenting the average marginal effects of the estimates. See the Details for more information.
- dodge_size
A number (typically between 0 and 0.3; the default is .06) indicating how much horizontal separation should appear between different submodels' coefficients when multiple submodels are graphed in a single plot. Lower values tend to look better when the number of models is small, while a higher value may be helpful when many submodels appear on the same plot.
- show_intercept
A logical constant indicating whether the coefficient of the intercept term should be plotted.
- show_stats
A logical constant indicating whether to show a table of model fitness statistics under the dot-whisker plot. The default is
TRUE.- stats_tb
Customized table of model fitness. The table should be in a
data.frame.- stats_digits
A numeric value specifying the digits to display in the fitness table. This parameter is relevant only when
show_stats = TRUE. Default is 3, providing a balance between precision and readability.- stats_compare
A logical constant to enable comparison of statistics in the fitness table. Applicable only when
show_stats = TRUE. The default value isFALSE. That is, it presents all the statistics across different modeling methods, yet potentially expanding the table's breadth. When set toTRUE, only the shared, comparable statistics are remained.- stats_verbose
A logical constant to turn on/off the toggle warnings and messages of model fits. The default is
FALSE.- stats_size
A numeric value determining the font size in the fitness table, effective only if
show_stats = TRUE. The standard setting is 10.- stats_padding
Defining the internal margins of the fitness table. Relevant when
show_stats = TRUE. Set by default tounit(c(4, 4), "mm"), allowing for a balanced layout. Further customization options refer totableGrob.- stats_layout
Adjusting the spacing between the dotwhisker plot and the fitness table. Effective when
show_stats = TRUE. The initial configuration isc(2, -1, 1), ensuring a coherent visual flow. Additional layout settings refer toplot_layout.- model_order
A character vector defining the order of the models when multiple models are involved.
- submodel_order
A character vector defining the order of the submodels when multiple submodels are involved.
- axis_switch
A logical constant indicating the position of variable labels and y axis ticks. Default is FALSE, when the variable label is on the right side, and y axis ticks is on the left size.
- by_2sd
When x is model object or list of model objects, should the coefficients for predictors that are not binary be rescaled by twice the standard deviation of these variables in the dataset analyzed, per Gelman (2008)? Defaults to
TRUE. Note that when x is a tidy data frame, one can useby_2sdto rescale similarly.- dot_args
A list of arguments specifying the appearance of the dots representing mean estimates. For supported arguments, see
geom_pointrangeh.- ...
Arguments to pass to
dwplot.
Value
The function returns a ggplot object.
Details
small_multiple, following Kastellec and Leoni (2007), provides a compact means of representing numerous regression models in a single plot.
Tidy data frames to be plotted should include the variables term (names of predictors), estimate (corresponding estimates of coefficients or other quantities of interest), std.error (corresponding standard errors), and model (identifying the corresponding model).
In place of std.error one may substitute conf.low (the lower bounds of the confidence intervals of each estimate) and conf.high (the corresponding upper bounds).
Alternately, small_multiple accepts as input a list of model objects that can be tidied by tidy (or parameters (with proper formatting)), or a list of such model objects.
Optionally, more than one set of results can be clustered to facilitate comparison within each model; one example of when this may be desirable is to compare results across samples. In that case, the data frame should also include a variable submodel identifying the submodel of the results.
To minimize the need for lengthy, distracting regression tables (often relegated to an appendix for dot-whisker plot users), dwplot incorporates optimal model fit statistics directly beneath the dot-whisker plots. These statistics are derived using the excellent performance functions and integrated at the plot's base via patchwork and tableGrob functions. For added flexibility, dwplot includes the stats_tb feature, allowing users to input customized statistics. Furthermore, a suite of stats_* functions is available for fine-tuning the presentation of these statistics, enhancing user control over the visual output.
References
Kastellec, Jonathan P. and Leoni, Eduardo L. 2007. "Using Graphs Instead of Tables in Political Science." *Perspectives on Politics*, 5(4):755-771.